在检索信息和搜集信息中实现web信息展示,核心在于设计网络爬虫模块,主要是全文搜索引擎模块。本文主要设计了全文搜索并实现页面搜集器的详细介绍,该工作流程影响到核心算法和数据的存储,克服了该技术难点,实现良好的实际运行和良好的效果,进一步改进引擎效果。
本网站基于B/S模式对该爬虫网站进行设计,并要求爬取的操作简单,多用户数据鲜明,开发一个爬虫网站实现对多用户管理,数据分层管理,并且把数据存储到指定的数据库中。区分出重复的网页,解决去重问题;加上主题的相关性;更快速的抓取数据;存储数据;实现数据可视化。
关键词:搜索引擎; 网络爬虫; 信息检索; 页面索引
使用python提供的开放源代码django应用框架,Django 更关注的是模型(Model)、模板(Template)和视图(Views),也就是MTV模式。
想要打开登录界面,可以使用操作如下:
(1) 安装python3.6 版本
(2) 安装 Django库 1.11.4版本 pip install Django==1.11.14
(3) 安装 selenium库 3.141.0 pip install selenium
(4) 安装 jieba库 0.39版本 pip install jieba
(5) 在命令行下进入 xxx\Web_Spider_Demo\mysite_login\的目录下,运行manage.py(运行方法:python manage.py runserver),成功运行后,打开浏览器(google),输入网页主页:127.0.0.1:8000/index。
(6) 在登录时,使用注册时候的账号密码就可以登录自己的界面,获取填写的数据是否和注册时候的信息进行对比,如果相同,就可以登录进入,使用该网站的功能。
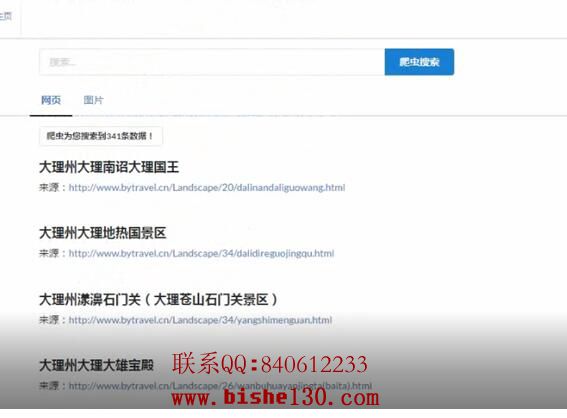
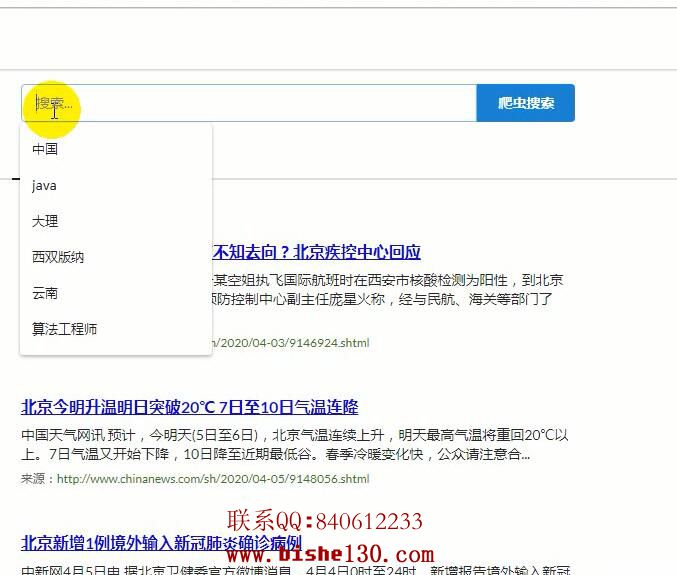
爬虫搜索
设计从网页中选择其中一部分的url,将url放入url队列中,对这些url中的链接进行解析,将内容下载下来,将其存储在固定的页面库中,建立对应的索引,从中抽取出所包含的所有链接信息如果分析中该url没有在缓存中出现过,则这个url调度下的队列就会被重新抓取一遍,直到抓取到对应的网页为止。完成一个完整的抓取过程,出现的爬虫有很多种类:
(1)批量型爬虫(Batch Crawler):分批次对数据进行抓取想要得到的目标和范围,当爬虫达到这个设定的目标后,即停止抓取过程。至于具体目标可能各异,也许是设定抓取一定数量的网页即可,也许是设定抓取消耗的时间等。
(2)增量型爬虫(Incremental Crawler):在抓取的过程中如果出现新增的网页,机制就会更新网页,可以实现通用的搜索引擎来实现增量的处理。
(3)垂直型爬虫(Focused Crawter):针对不同的特定主题内容,不同的特定行业的网页,就可以从互联网页而里找到与健康相关的页面内容即可,其他行业的内容不在考虑范围。垂直型爬虫一个最大的特点和难点就是:如何识别网页内容是否属于指定行业或者主题。
目录
1 引言 3
1.1 发展背景 4
1.2 研究现状 4
2 页面设计 6
2.1 基本工作原理 6
2.2 网页设计 6
2.2.1 注册 7
2.2.2 登录 8
2.2.3 爬虫搜索 8
3 功能实现 10
3.1 基本工作原理 10
3.2 jieba库 10
4 数据库设计 10
5 测试 11
5.1 设计问题 11
5.2 问题层次 12
5.3 测试评定 12
5.4 测试的设计 12
6 结语 13
参考文献 13
致谢 16